
그래프 간선의 분류
그래프의 구조와 특성을 파악하려면 어떤 방법을 이용해야 할까?
깊이우선탐색(DFS)은 그래프의 구조를 파악하는데 사용될 수 있다. 깊이우선탐색을 수행하면 그 과정에서 그래프의 모든 간선을 한번씩은 만나게 된다. 그중 일부 간선은 처음 발견한 정점으로 연결되어 있어서 우리가 따라갈 테고, 나머지는 무시하게 될 것이다. 하지만 이 간선들을 무시하지 않고 이들에 대한 정보를 수집하면 그래프의 구조에 대해 많은 것들을 알 수 있다.
어떤 그래프를 깊이 우선 탐색했을 때 탐색되는 간선들만 모아 보면 트리 형태를 띄게 된다. 예를들어 다음 왼쪽 그림에 있는 그래프를 0번 정점을 기준으로 깊이우선탐색을 했을 때, 오른쪽 그림의 굵은 검정색 간선들처럼 탐색이 될 것이다. 이처럼 깊이우선탐색으로 탐색했을 때, 탐색이 따라가는 간선들만을 모아 보면 트리 형태를 띄게 되는데 이 트리를 DFS 스패닝 트리(DFS Spanning Tree)라고 부른다. 이 그래프의 간선은 현재는 0번 정점을 기준으로 DFS를 수행했기 때문에 이렇게 분류되었지만, 다른 정점을 시작으로 DFS를 수행했다면 다른 형태로 간선들이 분류되었을 것이다.
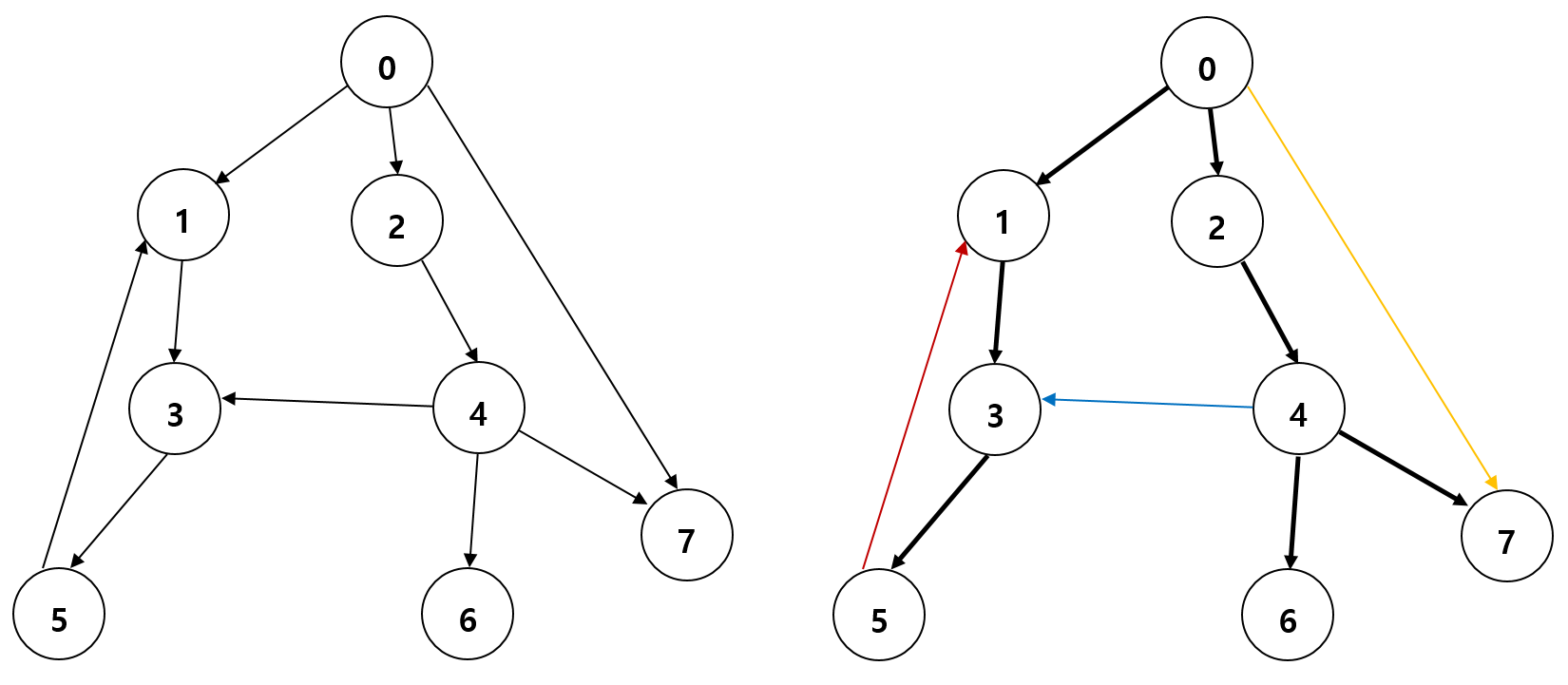
그래프의 DFS 스패닝 트리를 생성하고 나면 그래프의 모든 간선을 네 가지 형태로 분류할 수 있다.
1. 트리 간선
트리 간선은 스패닝 트리에 포함된 간선을 의미한다. 오른쪽 그래프에서는 검정색 굵은 간선들이 이에 해당된다.
2. 순방향 간선
순방향 간선은 스패닝 트리의 선조에서 자손으로 연결되지만 트리 간선이 아닌 간선을 의미한다. 오른쪽 그래프에서 노란색 간선이 이에 해당된다.
3. 역방향 간선
역방향 간선은 스패닝 트리의 자손에서 선조로 연결되는 간선을 의미한다. 오른쪽 그림에서 붉은색 간선이 이에 해당된다.
4. 교차 간선
교차 간선은 위 세 가지 분류를 제외한 나머지 간선들을 의미한다. 즉, 선조와 자손관계가 아닌 정점들 간에 연결된 간선들을 의미한다. 오른쪽 그림에서 파란색 간선이 이에 해당된다.
간선 분류 동작과정 및 구현
그래프의 간선 분류과정을 구현하려면 어떻게 접근해야할까?
일반적인 DFS 알고리즘으로 접근한다고 생각해보자. 0번정점에서부터 탐색을 수행한다고 했을 때 단순히 방문여부만 저장하는 일반 DFS에서는 어떤 정점이 다른 어떤 정점의 부모인지 혹은 자식인지 알 방법이 없다. 그러므로 방문여부 외에 추가적인 정보가 필요하다. 한 가지 방법은 각 정점을 방문할 때 이 정점이 몇 번째로 방문되었는지를 기록하는 것이다.
// DFS 방문 순서를 기록하는 배열
// 아직 방문하지 않은 상태인 경우인 -1로 초기화한다.
vector<int> indexes(V, -1);방문 순서를 indexes라는 배열에 기록하도록 하자. 그리고 DFS 탐색 과정 중 어떤 간선 (u, v)를 검사하는 과정에서 다음과 같이 상황을 나누어 생각해볼 수 있다.
1. 간선 (u, v)가 트리 간선이라면, v는 방문된 적이 없어야 한다.
2. 간선 (u, v)가 순방향 간선이라면, v는 u의 자손이어야 한다. 따라서 indexes[u] < indexes[v] 이다.
3. 간선 (u, v)가 역방향 간선이라면, v는 u의 선조여야 한다. 따라서 indexes[u] > indexes[v] 이다.
4. 간선 (u, v)가 교차 간선이라면, 위 모든 경우가 아니면서, dfs(v)가 종료된 후 dfs(u)가 호출되어야 한다.
1, 2, 3번 상황은 indexes와 방문 정보를 이용하여 분류할 수 있지만, 4번 상황의 경우 각 정점들에 대한 dfs탐색이 끝난는지를 판단할 추가적인 정보가 필요하다. 그러므로 배열을 하나 추가하여 dfs가 끝나는 경우 기록해주도록 한다.
// 각 정점에 대해 dfs 탐색이 끝났는지를 기록하는 배열
vector<bool> finished(V, false);
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
무향 그래프의 간선분류
무향 그래프의 간선은 어떻게 분류될 수 있을까?
무향 그래프의 모든 간선은 양방향으로 이동 가능하므로, 교차 간선이 존재할 수 없다. 간선 (u, v)가 교차 간선이기 위해서는 v가 먼저 방문된 후 u를 방문하지 않고 종료되어야 하는데, 무향 그래프의 경우 (u, v)를 통해 v->u로도 이동이 가능하기 때문에 이런 경우가 생길 수 없다. 또한 무향 그래프에서는 순방향 간선과 역방향 간선의 구분이 없다. 추가적으로 구현상에서 유의해야하는 부분이 있는데, 양방향 간선의 경우 항상 u -> v 이면 v -> u 이기 때문에 모든 트리 간선이 역방향 간선으로 분류될 수 있다. 그러므로 이 부분은 따로 예외처리 해주어야 한다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
사이클 존재 여부 확인
간선 구분의 또 다른 사용 예로 방향 그래프에 사이클이 존재하는지 확인하는 문제를 들 수 있다. 간선의 분류 중, 역방향 간선의 존재여부는 사이클의 존재여부와 동치이기 때문에 역방향 간선이 있는지만 확인하면 된다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
절단점
절단점(Articulation Point / Cut Vertex)이란 어떤 무향 그래프에서 이 정점과 인접한 간선들을 모두 지웠을 때 해당 컴포넌트가 두 개 이상으로 나뉘어지는 정점을 의미한다. 절단점을 찾는 문제는 현실 세계에서도 중요한 의미를 갖는다. 어떤 네트워크를 표현한 그래프에 절단점이 있다면, 이 그래프는 해당 라우터가 고장날 경우 마비될 것이다. 이처럼 그래프 상의 취약점을 빠르게 파악하기 위해 사용된다.
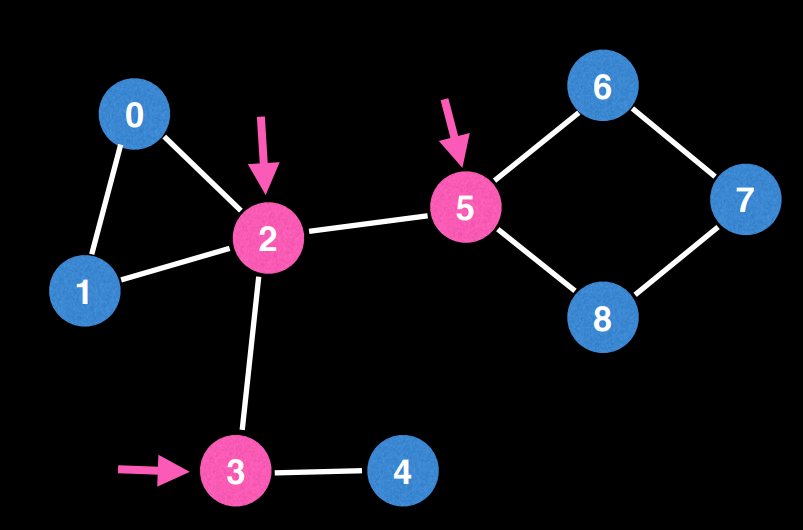
절단점의 구체적인 예를 확인해보자.
2번 정점이 제거된다면 그래프는 {0, 1}, {3, 4}, {5, 6, 7, 8} 총 3개의 컴포넌트로 분리된다.
5번 정점이 제거된다면 그래프는 {0, 1, 2, 3, 4}, {6, 7, 8} 총 2개의 컴포넌트로 분리된다.
3번 정점이 제거된다면 그래프는 {0, 1, 2, 5, 6, 7, 8}, {4} 총 2개의 컴포넌트로 분리된다.
그러프로 2, 3, 5번 정점은 절단점이다.
동작과정 및 구현
어떤 정점이 덜단점인지 확인하는 간단한 방법은 해당 정점을 그래프에서 삭제한 뒤 컴포넌트의 개수가 이전보다 늘어났는지를 확인하는 것이다. 하지만 이 방법으로 모든 정점의 절단점 여부를 확인하려면 깊이 우선 탐색을 V번 수행해야 한다. 그러나 탐색 과정에서 얻는 정보를 잘 이용하면 한 번의 깊이 우선 탐색만으로 그래프의 모든 절단점을 찾아낼 수 있다.
먼저 임의의 정점에서부터 깊이 우선 탐색을 수행해 DFS 스패닝 트리를 만든다. 이 때 어떤 정점 u가 절단점인지를 어떻게 알 수 있을까? 무향 그래프의 스패닝 트리에는 교차 간선이 없으므로, u와 연결된 정점들은 모두 u의 선조 아니면 자손이다. 다음 그래프를 보자.
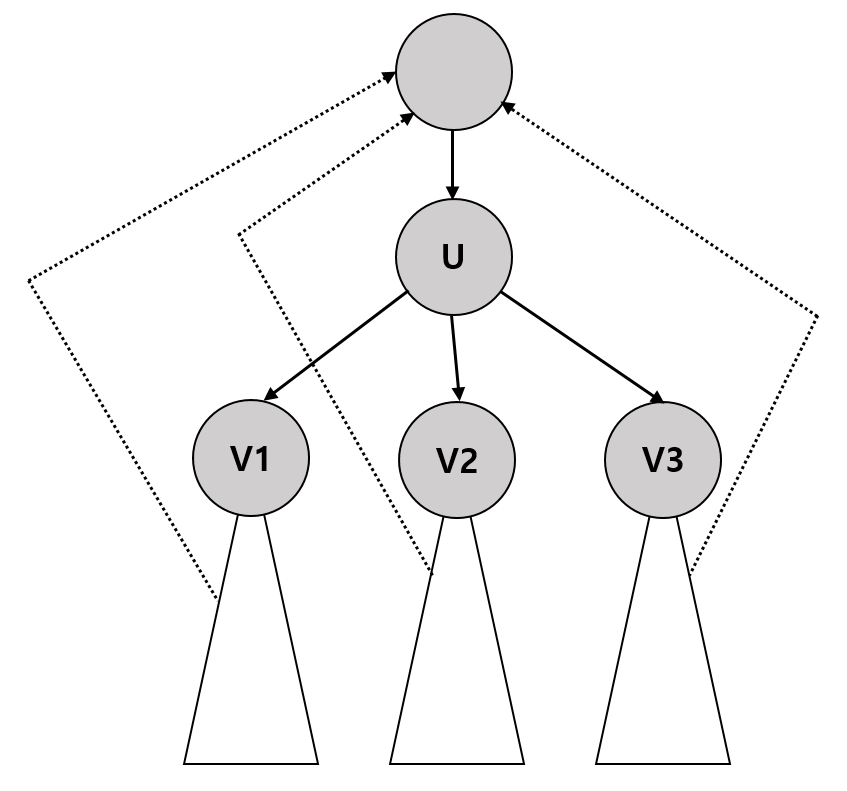
이 그래프에는 u의 서브트리로 v1, v2, v3가 있는데, 이 서브트리들은 서로 연결되어있지 않다. 만약 이들을 연결하는 간선이 있다면 교차 간선일 텐데, 무향 그래프에는 교차 간선이 있을 수 없기 때문이다. 따라서 u가 지워졌을 때 그래프가 쪼개지지 않는 유일한 경우는 그림에 그려진 것처럼 u의 선조와 자손들이 전부 역방향 간선으로 연결되어 있을 때 뿐이다. 이것을 확인하는 방법은 깊이 우선탐색을 수행하는 함수 dfs가 각 정점을 루트로 하는 서브트리에서 역방향 간선을 통해 갈 수 있는 정점의 최소 깊이를 반환하도록 하는 것이다. 만약 u의 자손들이 모두 역방향 간선을 통해 u의 선조로 올라갈 수 있다면 u는 절단점이 아니다. 그렇다면 u가 스패닝 트리의 루트라서 선조가 없다면 어떻게 될까? u는 무조건 절단점이라고 생각하기 쉽지만, 간과하기 쉬운 예외가 있다. 바로 자손이 하나도 없거나 하나밖에 없는 경우이다. 이 경우 u가 없어져도 그래프는 쪼개지지 않는다. 따라서 u가 루트인 경우 둘 이상의 자손을 가질 때만 절단점이 된다.
실제로 이 알고리즘을 구현할 때는 각 정점의 깊이를 비교하는 대신, 각 정점의 발견 순서를 비교하는 형태로 코드를 작성해 구현을 간단하게 할 수 있다. 우리가 알고 싶은 것은 해당 서브트리가 u의 조상 중 하나와 연결되어 있는지인데, u의 조상들은 항상 u보다 먼저 발견되었을 것이다. 따라서 깊이 우선 탐색 함수가 해당 정점을 루트로 하는 서브트리에서 역방향 간선을 통해 닿는 정점들의 최소 발견 순서를 반환하도록 하기만 하면 된다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
다리
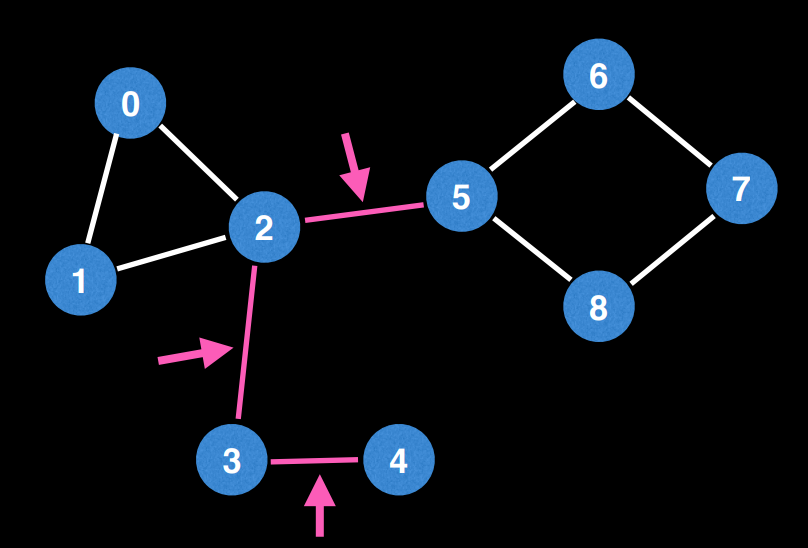
어떤 무향 그래프에서 이 간선을 제거했을 때 두 개의 컴포넌트로 분리된다면 그 간선을 다리(Bridge / Cut Edge)라고 부른다. 다음 그래프를 예로 들어보자.
(2, 3) 간선이 제거된다면 그래프는 {0, 1, 2, 5, 6, 7, 8}, {3, 4} 로 분리된다.
(2, 5) 간선이 제거된다면 그래프는 {0, 1, 2, 3, 4}, {5, 6, 7, 8} 로 분리된다.
(3, 4) 간선이 제거된다면 그래프는 {0, 1, 2, 3, 5, 6, 7, 8}, {4} 로 분리된다.
그러므로 (2, 3), (2, 5), (3, 4) 간선은 다리이다.
동작과정 및 구현
다리를 찾는 문제는 절단점을 찾는 문제를 간단히 변형해서 풀 수 있다. 중요한 점은 다리는 트리 간선일 수밖에 없다는 것이다. 어떤 간선 (u, v)가 순방향 간선이나 역방향 간선이라면 u와 v를 잇는 또 다른 경로가 있다는 것인데, 그러면 (u, v)는 결코 다리가 될 수 없다. 따라서 트리 간선들에 대해서만 이 간선이 다리인지 판정하면 된다. DFS 스패닝 트리 상에서 u가 v의 부모일 때, 트리 간선 (u, v)가 다리가 되기 위해서는 v를 루트로 하는 서브트리와 이 외의 점들을 연결하는 유일한 간선이 (u, v)여야 한다. 따라서 (u, v)를 제외한 역방향 간선으로u보다 높은 정점에 갈 수 없을 경우 (u, v)가 다리라고 판정할 수 있다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
강결합요소
무향 그래프와 달리 유향 그래프에서는 이중 결합 컴포넌트라는 개념이 존재하지 못한다. 방향 그래프에서는 두 정점이 간선을 통해 연결되어 있다고 해서 두 정점을 잇는 경로가 존재하는 것이 아니므로, 절단점의 개념도 유향 그래프에서는 그래도 사용할 수 없다. 이중 결합 컴포넌트와 비슷하지만 방향 그래프에서 정의되는 개념으로 강결합 컴포넌트(Strongly Connected Components, SCC)가 있다. 방향 그래프 상에서 두 정점 u, v에 대해 양 방향으로 가는 경로가 모두 있을 때 두 정점은 같은 SCC에 속해 있다고 말한다. 다음 그래프를 보자.
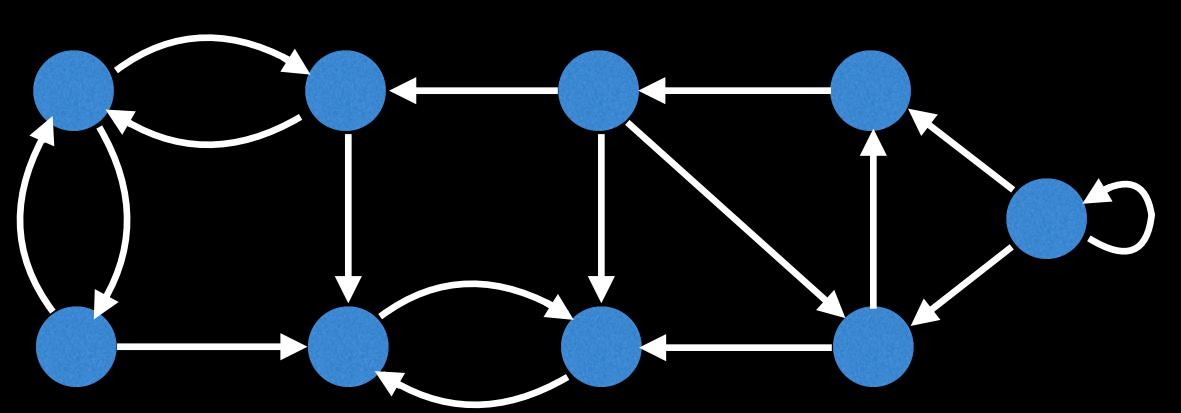
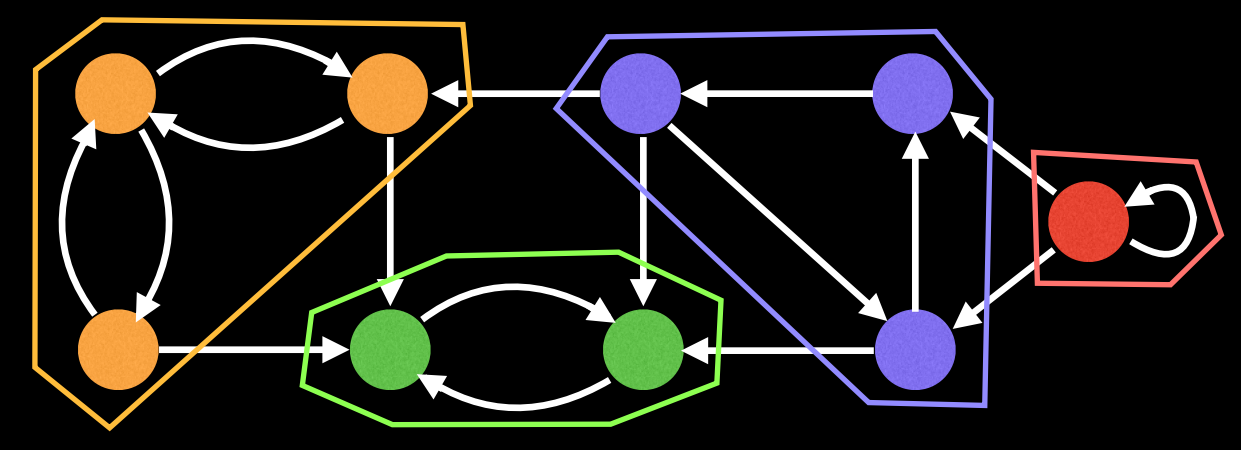
이 그래프에서 강결합요소를 표시하면 다음과 같이 분리될 것이다. 여기서 중요한 점은 각 강결합요소들 내부의 모든 정점들을 서로를 향한 경로가 존재한다는 것이다.
타잔 알고리즘
ㅇ
이미지 출처 (https://github.com/williamfiset/Algorithms)
'프로그래밍 > 알고리즘' 카테고리의 다른 글
| [Algorithm] 재귀 함수를 스택과 반복문으로 구현하기 (0) | 2024.08.08 |
|---|---|
| [Algorithm] 힙 (1) | 2024.02.12 |
| [Algorithm] 백트래킹 (0) | 2021.07.03 |
| [Algorithm] 유향 비순환 그래프 (0) | 2021.06.26 |
| [Algorithm] 최단 경로 (0) | 2021.06.26 |
그래프 간선의 분류
그래프의 구조와 특성을 파악하려면 어떤 방법을 이용해야 할까?
깊이우선탐색(DFS)은 그래프의 구조를 파악하는데 사용될 수 있다. 깊이우선탐색을 수행하면 그 과정에서 그래프의 모든 간선을 한번씩은 만나게 된다. 그중 일부 간선은 처음 발견한 정점으로 연결되어 있어서 우리가 따라갈 테고, 나머지는 무시하게 될 것이다. 하지만 이 간선들을 무시하지 않고 이들에 대한 정보를 수집하면 그래프의 구조에 대해 많은 것들을 알 수 있다.
어떤 그래프를 깊이 우선 탐색했을 때 탐색되는 간선들만 모아 보면 트리 형태를 띄게 된다. 예를들어 다음 왼쪽 그림에 있는 그래프를 0번 정점을 기준으로 깊이우선탐색을 했을 때, 오른쪽 그림의 굵은 검정색 간선들처럼 탐색이 될 것이다. 이처럼 깊이우선탐색으로 탐색했을 때, 탐색이 따라가는 간선들만을 모아 보면 트리 형태를 띄게 되는데 이 트리를 DFS 스패닝 트리(DFS Spanning Tree)라고 부른다. 이 그래프의 간선은 현재는 0번 정점을 기준으로 DFS를 수행했기 때문에 이렇게 분류되었지만, 다른 정점을 시작으로 DFS를 수행했다면 다른 형태로 간선들이 분류되었을 것이다.
그래프의 DFS 스패닝 트리를 생성하고 나면 그래프의 모든 간선을 네 가지 형태로 분류할 수 있다.
1. 트리 간선
트리 간선은 스패닝 트리에 포함된 간선을 의미한다. 오른쪽 그래프에서는 검정색 굵은 간선들이 이에 해당된다.
2. 순방향 간선
순방향 간선은 스패닝 트리의 선조에서 자손으로 연결되지만 트리 간선이 아닌 간선을 의미한다. 오른쪽 그래프에서 노란색 간선이 이에 해당된다.
3. 역방향 간선
역방향 간선은 스패닝 트리의 자손에서 선조로 연결되는 간선을 의미한다. 오른쪽 그림에서 붉은색 간선이 이에 해당된다.
4. 교차 간선
교차 간선은 위 세 가지 분류를 제외한 나머지 간선들을 의미한다. 즉, 선조와 자손관계가 아닌 정점들 간에 연결된 간선들을 의미한다. 오른쪽 그림에서 파란색 간선이 이에 해당된다.
간선 분류 동작과정 및 구현
그래프의 간선 분류과정을 구현하려면 어떻게 접근해야할까?
일반적인 DFS 알고리즘으로 접근한다고 생각해보자. 0번정점에서부터 탐색을 수행한다고 했을 때 단순히 방문여부만 저장하는 일반 DFS에서는 어떤 정점이 다른 어떤 정점의 부모인지 혹은 자식인지 알 방법이 없다. 그러므로 방문여부 외에 추가적인 정보가 필요하다. 한 가지 방법은 각 정점을 방문할 때 이 정점이 몇 번째로 방문되었는지를 기록하는 것이다.
// DFS 방문 순서를 기록하는 배열
// 아직 방문하지 않은 상태인 경우인 -1로 초기화한다.
vector<int> indexes(V, -1);방문 순서를 indexes라는 배열에 기록하도록 하자. 그리고 DFS 탐색 과정 중 어떤 간선 (u, v)를 검사하는 과정에서 다음과 같이 상황을 나누어 생각해볼 수 있다.
1. 간선 (u, v)가 트리 간선이라면, v는 방문된 적이 없어야 한다.
2. 간선 (u, v)가 순방향 간선이라면, v는 u의 자손이어야 한다. 따라서 indexes[u] < indexes[v] 이다.
3. 간선 (u, v)가 역방향 간선이라면, v는 u의 선조여야 한다. 따라서 indexes[u] > indexes[v] 이다.
4. 간선 (u, v)가 교차 간선이라면, 위 모든 경우가 아니면서, dfs(v)가 종료된 후 dfs(u)가 호출되어야 한다.
1, 2, 3번 상황은 indexes와 방문 정보를 이용하여 분류할 수 있지만, 4번 상황의 경우 각 정점들에 대한 dfs탐색이 끝난는지를 판단할 추가적인 정보가 필요하다. 그러므로 배열을 하나 추가하여 dfs가 끝나는 경우 기록해주도록 한다.
// 각 정점에 대해 dfs 탐색이 끝났는지를 기록하는 배열
vector<bool> finished(V, false);
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
무향 그래프의 간선분류
무향 그래프의 간선은 어떻게 분류될 수 있을까?
무향 그래프의 모든 간선은 양방향으로 이동 가능하므로, 교차 간선이 존재할 수 없다. 간선 (u, v)가 교차 간선이기 위해서는 v가 먼저 방문된 후 u를 방문하지 않고 종료되어야 하는데, 무향 그래프의 경우 (u, v)를 통해 v->u로도 이동이 가능하기 때문에 이런 경우가 생길 수 없다. 또한 무향 그래프에서는 순방향 간선과 역방향 간선의 구분이 없다. 추가적으로 구현상에서 유의해야하는 부분이 있는데, 양방향 간선의 경우 항상 u -> v 이면 v -> u 이기 때문에 모든 트리 간선이 역방향 간선으로 분류될 수 있다. 그러므로 이 부분은 따로 예외처리 해주어야 한다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
사이클 존재 여부 확인
간선 구분의 또 다른 사용 예로 방향 그래프에 사이클이 존재하는지 확인하는 문제를 들 수 있다. 간선의 분류 중, 역방향 간선의 존재여부는 사이클의 존재여부와 동치이기 때문에 역방향 간선이 있는지만 확인하면 된다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
절단점
절단점(Articulation Point / Cut Vertex)이란 어떤 무향 그래프에서 이 정점과 인접한 간선들을 모두 지웠을 때 해당 컴포넌트가 두 개 이상으로 나뉘어지는 정점을 의미한다. 절단점을 찾는 문제는 현실 세계에서도 중요한 의미를 갖는다. 어떤 네트워크를 표현한 그래프에 절단점이 있다면, 이 그래프는 해당 라우터가 고장날 경우 마비될 것이다. 이처럼 그래프 상의 취약점을 빠르게 파악하기 위해 사용된다.
절단점의 구체적인 예를 확인해보자.
2번 정점이 제거된다면 그래프는 {0, 1}, {3, 4}, {5, 6, 7, 8} 총 3개의 컴포넌트로 분리된다.
5번 정점이 제거된다면 그래프는 {0, 1, 2, 3, 4}, {6, 7, 8} 총 2개의 컴포넌트로 분리된다.
3번 정점이 제거된다면 그래프는 {0, 1, 2, 5, 6, 7, 8}, {4} 총 2개의 컴포넌트로 분리된다.
그러프로 2, 3, 5번 정점은 절단점이다.
동작과정 및 구현
어떤 정점이 덜단점인지 확인하는 간단한 방법은 해당 정점을 그래프에서 삭제한 뒤 컴포넌트의 개수가 이전보다 늘어났는지를 확인하는 것이다. 하지만 이 방법으로 모든 정점의 절단점 여부를 확인하려면 깊이 우선 탐색을 V번 수행해야 한다. 그러나 탐색 과정에서 얻는 정보를 잘 이용하면 한 번의 깊이 우선 탐색만으로 그래프의 모든 절단점을 찾아낼 수 있다.
먼저 임의의 정점에서부터 깊이 우선 탐색을 수행해 DFS 스패닝 트리를 만든다. 이 때 어떤 정점 u가 절단점인지를 어떻게 알 수 있을까? 무향 그래프의 스패닝 트리에는 교차 간선이 없으므로, u와 연결된 정점들은 모두 u의 선조 아니면 자손이다. 다음 그래프를 보자.
이 그래프에는 u의 서브트리로 v1, v2, v3가 있는데, 이 서브트리들은 서로 연결되어있지 않다. 만약 이들을 연결하는 간선이 있다면 교차 간선일 텐데, 무향 그래프에는 교차 간선이 있을 수 없기 때문이다. 따라서 u가 지워졌을 때 그래프가 쪼개지지 않는 유일한 경우는 그림에 그려진 것처럼 u의 선조와 자손들이 전부 역방향 간선으로 연결되어 있을 때 뿐이다. 이것을 확인하는 방법은 깊이 우선탐색을 수행하는 함수 dfs가 각 정점을 루트로 하는 서브트리에서 역방향 간선을 통해 갈 수 있는 정점의 최소 깊이를 반환하도록 하는 것이다. 만약 u의 자손들이 모두 역방향 간선을 통해 u의 선조로 올라갈 수 있다면 u는 절단점이 아니다. 그렇다면 u가 스패닝 트리의 루트라서 선조가 없다면 어떻게 될까? u는 무조건 절단점이라고 생각하기 쉽지만, 간과하기 쉬운 예외가 있다. 바로 자손이 하나도 없거나 하나밖에 없는 경우이다. 이 경우 u가 없어져도 그래프는 쪼개지지 않는다. 따라서 u가 루트인 경우 둘 이상의 자손을 가질 때만 절단점이 된다.
실제로 이 알고리즘을 구현할 때는 각 정점의 깊이를 비교하는 대신, 각 정점의 발견 순서를 비교하는 형태로 코드를 작성해 구현을 간단하게 할 수 있다. 우리가 알고 싶은 것은 해당 서브트리가 u의 조상 중 하나와 연결되어 있는지인데, u의 조상들은 항상 u보다 먼저 발견되었을 것이다. 따라서 깊이 우선 탐색 함수가 해당 정점을 루트로 하는 서브트리에서 역방향 간선을 통해 닿는 정점들의 최소 발견 순서를 반환하도록 하기만 하면 된다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
다리
어떤 무향 그래프에서 이 간선을 제거했을 때 두 개의 컴포넌트로 분리된다면 그 간선을 다리(Bridge / Cut Edge)라고 부른다. 다음 그래프를 예로 들어보자.
(2, 3) 간선이 제거된다면 그래프는 {0, 1, 2, 5, 6, 7, 8}, {3, 4} 로 분리된다.
(2, 5) 간선이 제거된다면 그래프는 {0, 1, 2, 3, 4}, {5, 6, 7, 8} 로 분리된다.
(3, 4) 간선이 제거된다면 그래프는 {0, 1, 2, 3, 5, 6, 7, 8}, {4} 로 분리된다.
그러므로 (2, 3), (2, 5), (3, 4) 간선은 다리이다.
동작과정 및 구현
다리를 찾는 문제는 절단점을 찾는 문제를 간단히 변형해서 풀 수 있다. 중요한 점은 다리는 트리 간선일 수밖에 없다는 것이다. 어떤 간선 (u, v)가 순방향 간선이나 역방향 간선이라면 u와 v를 잇는 또 다른 경로가 있다는 것인데, 그러면 (u, v)는 결코 다리가 될 수 없다. 따라서 트리 간선들에 대해서만 이 간선이 다리인지 판정하면 된다. DFS 스패닝 트리 상에서 u가 v의 부모일 때, 트리 간선 (u, v)가 다리가 되기 위해서는 v를 루트로 하는 서브트리와 이 외의 점들을 연결하는 유일한 간선이 (u, v)여야 한다. 따라서 (u, v)를 제외한 역방향 간선으로u보다 높은 정점에 갈 수 없을 경우 (u, v)가 다리라고 판정할 수 있다.
소스코드
insooneelife/AlgorithmTutorial
알고리즘 튜토리얼. Contribute to insooneelife/AlgorithmTutorial development by creating an account on GitHub.
github.com
강결합요소
무향 그래프와 달리 유향 그래프에서는 이중 결합 컴포넌트라는 개념이 존재하지 못한다. 방향 그래프에서는 두 정점이 간선을 통해 연결되어 있다고 해서 두 정점을 잇는 경로가 존재하는 것이 아니므로, 절단점의 개념도 유향 그래프에서는 그래도 사용할 수 없다. 이중 결합 컴포넌트와 비슷하지만 방향 그래프에서 정의되는 개념으로 강결합 컴포넌트(Strongly Connected Components, SCC)가 있다. 방향 그래프 상에서 두 정점 u, v에 대해 양 방향으로 가는 경로가 모두 있을 때 두 정점은 같은 SCC에 속해 있다고 말한다. 다음 그래프를 보자.
이 그래프에서 강결합요소를 표시하면 다음과 같이 분리될 것이다. 여기서 중요한 점은 각 강결합요소들 내부의 모든 정점들을 서로를 향한 경로가 존재한다는 것이다.
타잔 알고리즘
ㅇ
이미지 출처 (https://github.com/williamfiset/Algorithms)
'프로그래밍 > 알고리즘' 카테고리의 다른 글
| [Algorithm] 재귀 함수를 스택과 반복문으로 구현하기 (0) | 2024.08.08 |
|---|---|
| [Algorithm] 힙 (1) | 2024.02.12 |
| [Algorithm] 백트래킹 (0) | 2021.07.03 |
| [Algorithm] 유향 비순환 그래프 (0) | 2021.06.26 |
| [Algorithm] 최단 경로 (0) | 2021.06.26 |